


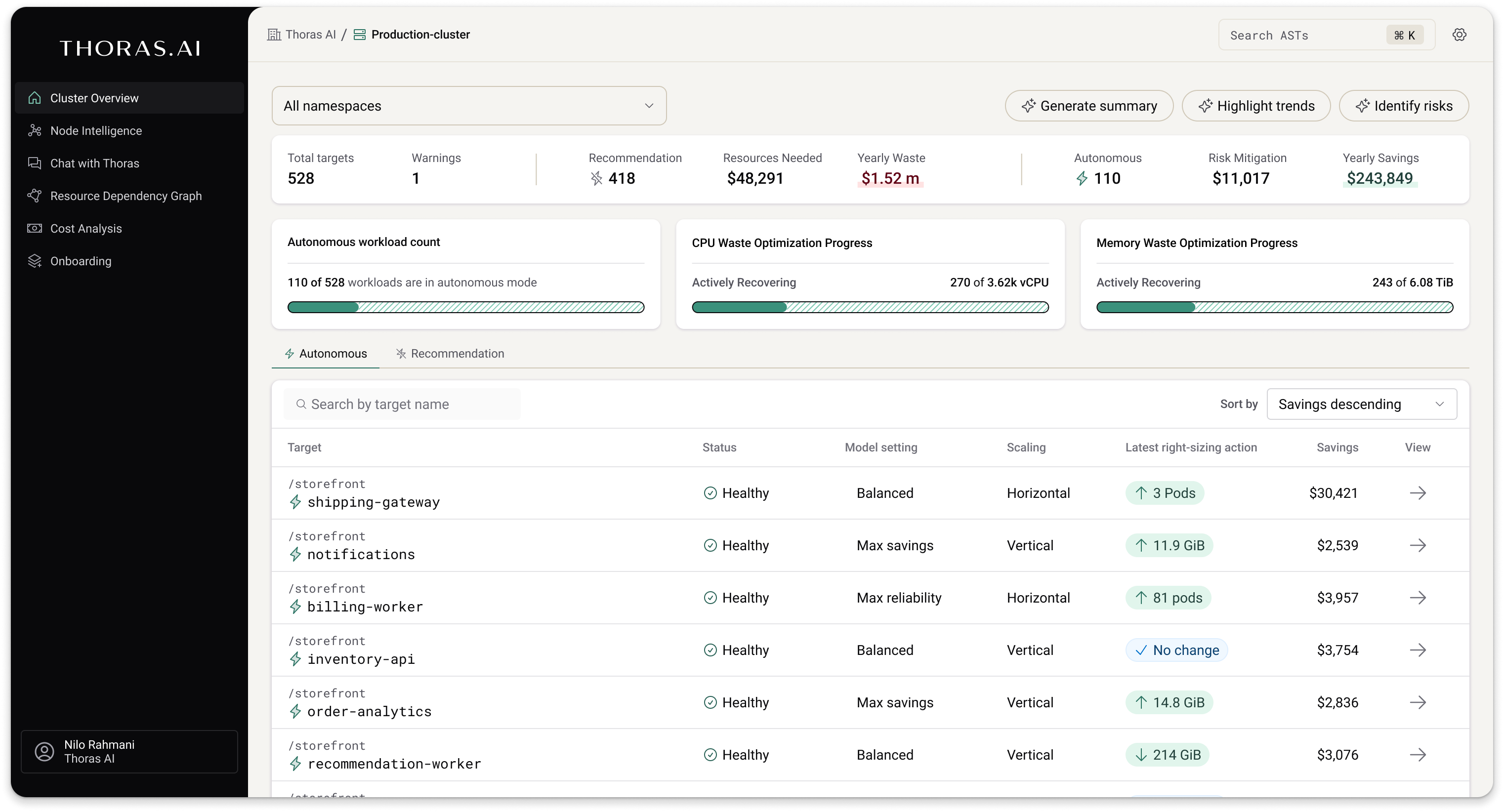
Compute Efficiency, Designed for Production.
Thoras adapts compute infrastructure to unique usage patterns, redefining how systems respond to demand- maintaining stable performance, reducing waste at scale, and keeping utilization aligned so infrastructure never becomes the constraint.
Trusted by high-performing engineering teams
.png)
Built for the Pragmatic Engineer. Designed for the Leader Who Plans.
Proven to handle mission-critical infrastructure at enterprise scale.
What Compounds Over Time
Performance Stability
Workloads maintain consistent behavior as demand fluctuates and complexity rises, avoiding degradation during growth.
Decision Consistency
Infrastructure decisions remain aligned as environments multiply, reducing drift and unexpected outcomes at scale.
Capital Efficiency
Compute investment produces more usable output over time, limiting waste as systems and demand grow.
Why is Being Predictive so Important?
When you can reliably forecast demand, you no longer have to choose between performance and overspending.
Most teams run at only 50% utilization — wasting cloud spend just to avoid risk.
With Thoras, teams confidently run at 85%+ utilization — without sacrificing reliability.
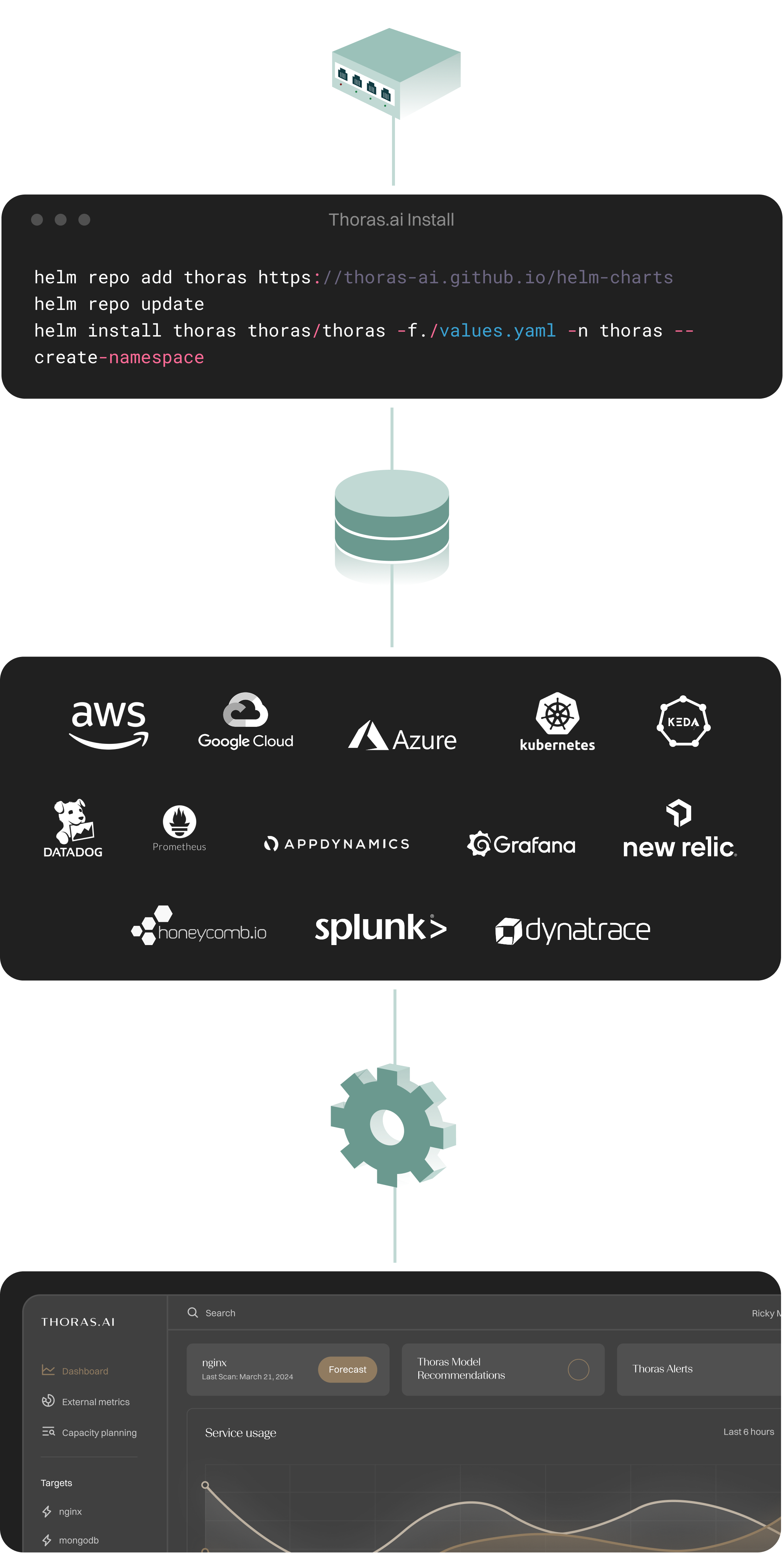
Entirely Air-Gapped & Installs In 15 minutes
Install Thoras with One Command
Deploy Thoras with a single Helm chart. No external APIs. No complex setup. Once installed, Thoras begins analyzing real-time traffic and historical workload behavior, instantly.

Connect to Your Existing Stack
Connect Thoras to Prometheus, Datadog, or Grafana to stream live telemetry — CPU/GPU, memory, request metrics. Enrich it with real-world signals like launches or traffic spikes to give Thoras full context.
Define Goals — Thoras Handles the Rest
Tell Thoras what matters most: reliability, efficiency, or cost. From there, it continuously adapts your infrastructure to meet demand — automatically, and without tuning thresholds.
Buy through AWS or GCP marketplaces


How Does Thoras Predict So Precisely?

Thoras Ingests Time-Series Metrics
From your full observability stack — including Prometheus, Datadog, and Splunk — to understand workload behavior minute by minute.

Understand What’s Driving Demand
Correlate infrastructure usage with real-world events — like product launches, campaigns, or sudden traffic spikes — to scale preemptively, not reactively.

Learns and Predicts Automatically
Thoras combines historical trends and live signals to forecast future resource needs, no thresholds, no tuning, just adaptive scaling that stays ahead.


GPU and CPU Scaling That Thinks in Every Direction
Thoras analyzes workload behavior and predicts demand before it happens. It then chooses the right mix of vertical and horizontal scaling for each service, automatically.
No restarts. No thresholds. No tuning. Just perfectly fitted workloads.

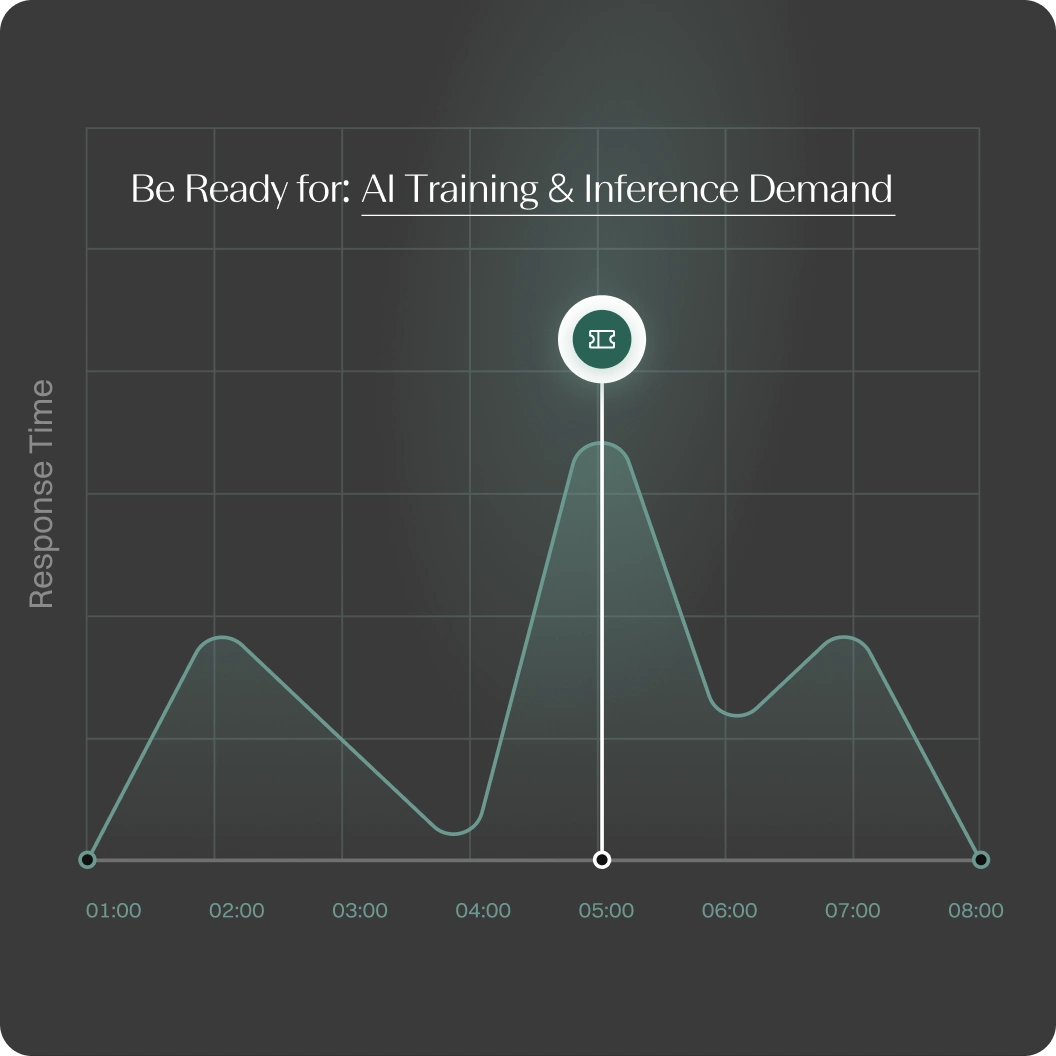
Capacity Planning With Real-World Data
Thoras doesn’t just react to system metrics, it anticipates demand using real-world signals like product launches, user growth, ad traffic, business hours, and more.
By combining internal telemetry with external events, Thoras ensures your infrastructure scales proactively and intelligently, even when traffic patterns are unpredictable.
Your Cluster, on Autopilot
Once installed, Thoras scales your workloads for you — no tuning, no babysitting, no YAML.
Thoras fades into the background, and scaling is no longer a daily task. It just works, so your team can focus on shipping, not sizing.












.webp)
See the Value, Not Just the Graphs
Thoras doesn’t just optimize your infrastructure, it shows you exactly how much you’re saving. See the real cost impact of predictive autoscaling with per-workload breakdowns.
For every service, Thoras surfaces the before-and-after: current monthly cost, optimized cost, and total savings, all without drowning you in FinOps tooling.
Frequently Asked Questions
Can Thoras help optimize my GPUs?
Yes. Thoras can forecast GPU workload demand and proactively scale your GPU resources to match upcoming needs. This means you can reduce idle GPU time, avoid last-minute provisioning delays, and ensure availability for high-priority workloads—whether for training, inference, or other compute-heavy jobs. By automatically rightsizing and scheduling GPU capacity based on predicted usage patterns, Thoras helps you run more efficiently while keeping costs under control.
We're migrating K8s to another environment, how can Thoras help?
Migrating comes with zero margin for error. Thoras gives you precision autoscaling without relying on HPA, VPA, or cloud-managed services. Our ML models adapt to your workloads and infrastructure, forecasting demand and allocating resources before spikes hit. You get cloud-grade elasticity on bare metal, without wasting a dime or risking downtime.
We're newly adopting K8s, how would Thoras help?
Don’t start with outdated tools. Most teams spend months tuning autoscalers, guessing resource requests, and reacting to noisy alerts. Thoras eliminates all of that. From day one, Thoras learns your workloads, makes resource decisions for you, and prevents scaling issues before they happen. You skip the growing pains and get straight to running production-ready systems, right.
Why does it matter to be predictive?
Because reactive tools lose you money, performance, and trust. By the time HPA notices a traffic spike, your users already feel the latency. By the time you respond to alerts, your team is already in firefighting mode. Thoras doesn’t wait. It forecasts demand based on historical usage and live signals, scaling just in time to avoid slowdowns, outages, or costly overprovisioning. Predictive means you never have to choose between safety and efficiency again.
Our K8s adoption is extremely mature, why would we introduce Thoras now?
Because maturity shouldn’t mean maintenance hell. If your team is still babysitting HPA thresholds, tuning requests, or manually right-sizing, that’s not maturity, that’s toil. Thoras replaces reactive tooling with proactive intelligence that runs 24/7. It finds the savings you missed, prevents the incidents you’ve come to accept, and scales your expertise without growing your team. You’ve already invested in Kubernetes, Thoras makes that investment self-optimizing.
If my traffic is predictable, why would I still need Thoras?
Predictable traffic doesn’t mean predictable systems. Rollouts, restarts, and cascading failures still happen. Thoras doesn’t just forecast traffic — it analyzes infrastructure signals, service dependencies, and real-world usage patterns to proactively prevent waste and performance degradation. Even if your traffic looks the same every day, we find the hidden inefficiencies and fix them before they hurt you.
Trusted by Engineers That Can’t Afford Mistakes





You Build. Thoras Rightsizes.
Thoras predicts demand before it happens, so you always have the right resources at the right time. Eliminate overprovisioning, slash cloud waste, and ensure reliability without manual tuning.

“We’re excited to support Nilo, Jen, and the Thoras team. As thesis-driven investors, we’ve been seeking the next generation of software that tackles major SRE and DevOps challenges. Thoras is achieving impressive results in a short amount of time and addressing critical cloud costs and uptime issues faced by companies today.”

Trial Thoras for free, and start scaling immediately.
Take back your sleep.
No more guesswork, no more 2 AM fire drills — just the right capacity, the right data, at the right time.
Book a Demo




© 2025 Thoras.ai. All rights reserved.